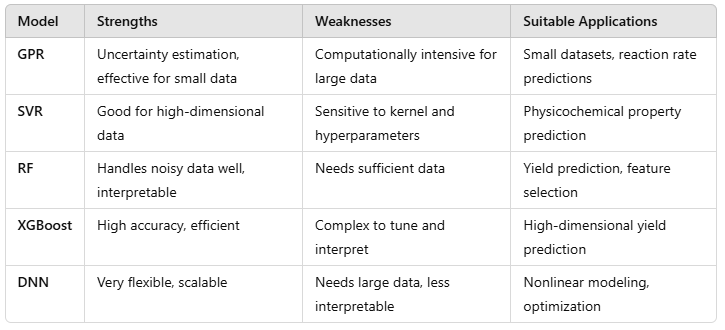
Data-driven Modelling#
This document provides an overview of data-driven modeling techniques frequently used in chemical and biochemical engineering for predictive modeling, optimization, and process control. Each model has unique strengths and is suitable for different types of data and tasks. Here, we introduce the following models:
Gaussian Process Regression (GPR)
Support Vector Regression (SVR)
Random Forests (RF)
XGBoost
Deep Neural Networks (DNN)
1. Gaussian Process Regression (GPR)#
Gaussian Process Regression (GPR) is a non-parametric, probabilistic model that assumes a Gaussian distribution for data points. This model is well-suited for applications with small datasets and when uncertainty estimation is valuable.
Characteristics:
Provides a probability distribution over possible functions that fit the data.
Useful for small datasets due to high computational cost for large datasets.
Naturally incorporates uncertainty estimation, which is helpful in safety-critical applications.
Common Applications:
Prediction of reaction rates and yield with small data.
Process control where uncertainty quantification is important.
Advantages:
Provides confidence intervals for predictions.
Captures nonlinear relationships in data.
Limitations:
Computationally intensive for large datasets.
Sensitive to the choice of kernel function (e.g., RBF kernel).
2. Support Vector Regression (SVR)#
Support Vector Regression (SVR) is a type of Support Vector Machine (SVM) adapted for regression tasks. It is particularly effective in high-dimensional spaces and can handle nonlinear relationships using kernel functions.
Characteristics:
Constructs a hyperplane in a high-dimensional space that best fits the data.
The margin around the hyperplane is controlled by an error tolerance (epsilon) and penalty parameter (C).
Common Applications:
Predicting physicochemical properties (e.g., viscosity, solubility).
Modeling complex relationships in reaction conditions and yields.
Advantages:
Works well with high-dimensional data.
Flexible with choice of kernel functions for nonlinearity (e.g., RBF, polynomial).
Limitations:
Requires tuning of hyperparameters (C, epsilon).
Less interpretable compared to simpler models like linear regression.
3. Random Forests (RF)#
Random Forests (RF) are ensemble models that use a collection of decision trees to make predictions. Each tree is trained on a random subset of the data, and the final prediction is an average (for regression) or majority vote (for classification).
Characteristics:
Ensemble method that reduces overfitting by averaging multiple decision trees.
Effective in handling high-dimensional and noisy data.
Common Applications:
Predicting reaction yields and conversion rates.
Feature selection and importance analysis.
Advantages:
Robust to overfitting and can handle large datasets well.
Provides feature importance metrics for interpretability.
Limitations:
Can be less accurate for datasets with strong temporal dependencies.
Requires sufficient data to perform well, particularly with many variables.
4. XGBoost#
XGBoost (eXtreme Gradient Boosting) is an optimized version of gradient-boosted decision trees, designed for speed and accuracy. It is highly popular in data-driven modeling due to its efficiency and competitive performance.
Characteristics:
Sequentially builds decision trees, where each tree corrects errors made by the previous one.
Optimized for computational speed and resource efficiency.
Common Applications:
Yield prediction, particularly with complex and high-dimensional data.
Process parameter optimization and sensitivity analysis.
Advantages:
Highly efficient and can handle large datasets.
Incorporates regularization to control overfitting.
Limitations:
Requires careful tuning of hyperparameters (e.g., learning rate, number of trees).
Complex to interpret due to sequential nature of boosting
5. Deep Neural Networks (DNN)#
Deep Neural Networks (DNN) are multilayered networks of artificial neurons designed to model complex, nonlinear relationships in data. They are highly flexible and can approximate intricate functions, making them suitable for many chemical and biochemical engineering applications.
Characteristics:
Composed of multiple layers of neurons, including input, hidden, and output layers.
Each neuron applies a non-linear transformation to its inputs, allowing the model to capture complex patterns.
Common Applications:
Modeling nonlinear relationships in large, high-dimensional datasets.
Predictive maintenance, fault detection, and optimization tasks.
Advantages:
Highly flexible and powerful for capturing complex, nonlinear relationships.
Scalable to very large datasets with appropriate hardware (e.g., GPUs).
Limitations:
Requires large datasets to avoid overfitting and realize full potential.
Often viewed as a “black box,” making interpretability challenging.
Model Comparison and Selection#